Sed и awk относятся к категории недооцениваемых Linux-утилит. Хотя на первый взгляд они могут показаться несколько сложными, если вам когда-либо необходимо было производить повторяющиеся изменения с вашим текстом или анализировать какой-либо текст, пользу Sed и Awk сложно переоценить.
Итак, кто они? Как они используются? И как, совместив их, можно легко анализировать текстовую информацию?
Что такое Sed?
Sed был разработан в 1971 году в Bell Labs легендарным пионером компьютеров Lee E. McMahon.
Название утилиты расшифровывается как «stream editor» — редактор потоков – и это то, что он делает. Она позволяет вам редактировать файлы или потоки текста автоматически с помощью компактного и простого, хотя и полного по Тьюрингу языка программирования.
Он работает очень просто: считывает текст в буфер построчно. Для каждой строчки, где это применимо, он будет выполнять заданные инструкции.
Например, если кто-то написал Sed-скрипт, который заменяет слово «beer» на «soda», а затем применил его к текстовому файлу, который содержал текст «99 Bottles of Beer on the Wall», он бы прошел по всем строчкам и в этой строчке заменил бы слова так, что она выглядела бы как «99 Bottles of Soda on the Wall» – и так далее.
Самый простой скрипт Sed – это Hello World. Здесь мы используем Unix-утилиту Echo, которая просто печатает строку, чтобы напечатать «Hello World». Но мы перенаправляем это в Sed и просим его заменить World на Dave.
echo «Hello World» | sed s/world/Dave
Вы также можете комбинировать sed-инструкции в файлах, если вам нужно проводить какое-либо более усложненное редактирование. Например, я собираюсь взять песню Take On Me и заменить каждое вхождение «I», «Me» и «My» на Greg.
Во-первых, я помещу слова песни в текстовый файл под названием text.txt. Затем я открою свой предпочитаемый текстовый редактор (мой любимый – Vim, но Nano и Gedit – тоже отличный вариант) и добавлю туда следующие строчки. Убедитесь, что созданный вами файл заканчивается на .sed.
Вы можете заметить, что в примере выше я повторялся (например, s/me/Greg/ и s/Me/Greg/). Это сделано из-за того, что некоторые версии Sed, например, та, которая поставляется с Mac OS X, не поддерживает нечувствительность к синтаксису. Следовательно, нам приходится писать две sed-инструкции для каждого слова, чтобы утилита понимала различные варианты слова.
Это не работает идеально – можете подумать вы, потому что я вручную делал это для каждого слова. Но пока что мы просто используем это как упражнение для демонстрации того, как вы можете группировать Sed-инструкции в один скрипт, а затем выполнять их с помощью одной-единственной команды.
Затем нам нужно выполнить файл. Чтобы сделать это, выполним следующую команду:
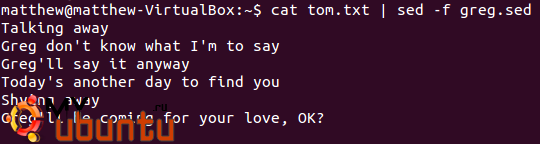
cat tom.txt | sed -f greg.sed
Теперь остановимся и посмотрим, что делает эта команда. Некоторые читатели могут заметить, что здесь мы не используем echo, а используем cat. Это происходит потому, что cat напечатает полное содержимое файла, а echo – только имя файла. Вы также можете заметить, что мы запускаем Sed с флагом –f. Это позволяет sed открыть скрипт как файл.
Вот результат работы:
Также стоит заметить, что Sed поддерживает регулярные выражения (regex). Они позволяют вам определять шаблоны в тексте, используя особенный и сложный синтаксис.
Вот пример того, как это может работать. Мы собираемся взять слова вышеупомянутой песни и использовать regex, чтобы напечатать каждую строчку, которая не начинается с Take.
cat tom.txt | sed /^Take/d
sed-regex-take
Sed, конечно, очень полезен. Но он даже еще более производителен, когда он скомбинирован с Awk.
Что такое Awk?
Awk, как и Sed – это язык программирования, созданный для работы с большими объемами текста. Но sed создан для обработки и редактирования текста, а awk в основном используется как инструмент для анализа и отчетов по тексту.
Как и sed, Awk был создан в семидесятых в Bell Labs. Его имя не содержит отсылку к функциям приложения, но, скорее, к фамилиям авторов — Alfred Aho, Peter Weinberger и Brian Kernaghan.
Awk работает, считывая текстовый файл или входной поток построчно. Каждая строчка сканируется на соответствие заданного шаблону. Если соответствие находится, производится желаемое действие.
Но хотя Sed и Awk могут быть похожи по описанию, это два совершенно разных языка, разрабатывавшиеся под влиянием различных философий. Awk больше похож на некоторые обычные языки, вроде C, Python и Bash. В нем есть такие вещи, как функции, и C-подобное отношение к сущностям вроде итераций и переменных. Он больше похож на язык программирования.
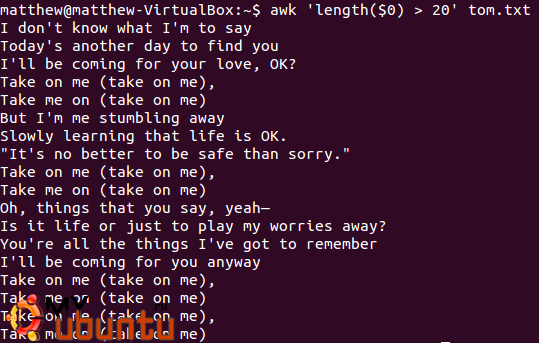
Поэтому давайте попробуем его. Используя слова песни Take On Me, мы собираемся вывести все строчки длиной более двадцати символов.
awk ‘ length($0) > 80 ‘ tom.txt
Следующий пример был взят из официальной документации Awk. Это отличный пример потенциала этого производительного, хотя и крохотного языка. Это также является отличной демонстрацией того, как работают итерации и переменные в этом языке. Для начала давайте создадим файл под названием «WordCount.awk» и добавим в него следующие строчки.
{
for (i = 1; i <= NF; i++)
freq[$i]++
}
END {
for (word in freq)
printf «%s\t%d\n», word, freq[word]
}
Сохраните его и выполните с помощью следующей команды:
awk -f WordCount.awk tom.txt
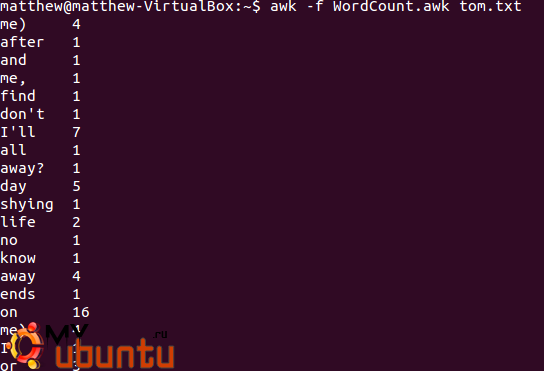
Здорово, верно? Возможно, вы заметите, что они не отсортированы. Вы можете отсортировать результата, используя Unix-утилиту sort, но мы оставим это на одну из следующих статей.
Комбинирование двух утилит
Awk и Sed очень производительны при их сочетании. Вы можете сделать, разделяя команды при помощи символа |.
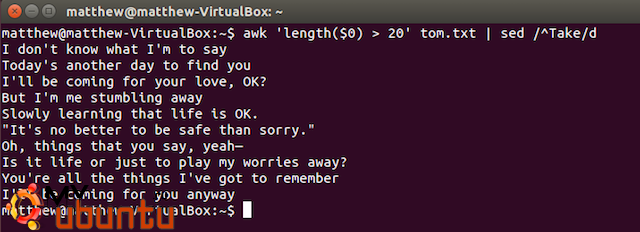
Давайте попробуем сделать это: мы попытаемся перечислить все строчки в Take On Me, содержащие больше 20 символов, используя Awk. Затем мы уберем все строчки, которые начинаются с Take. Вместе это будет выглядеть как-то так:
awk ‘length($0)>20’ tom.txt | sed /^Take/d
И производить следующий вывод:
Теперь давайте еще больше улучшим это. Мы удалим все строчки, которые начинаются с Take, и отправим их в Awk, где мы посчитаем, сколько раз встречается каждое слово. Это выглядит примерно так:
cat tom.txt | sed /^Take/d | awk -f WordCount.awk
Мощь sed и awk
Мало что можно объяснить в одной небольшой статье. Но я надеюсь, что я проиллюстрировал то, какими неоспоримо производителями являютяс Sed и Awk.
Итак, зачем вам это нужно? Sed и awk отлично подходят, например, для обработки лог-файлов. Это особенно полезно, когда вы пытаетесь найти проблему на своем сервере, или смотрите логи доступа для того, чтобы понять, как кому-то удалось взломать его.
А как вы используете sed и awk? Вы считаете эти утилиты полезными?